![]()
|
Alle Programme können von hier heruntergeladen werden. |
|
|
Problembeschreibung |
|
Bei der Charakterisierung von Objekten werden oft die Gemeinsamkeiten und Unterschiede von Objekteigenschaften (Attribute, Properties) herangezogen und die Objekte mit gleichartigen Eigenschaften in Klassen eingeteilt. Ausgehend von einer Datensammlung (das Training-Set) bei der die Klasseneinteilung bereits vorgenommen wurde, soll ein Verfahren entwickelt werden, um ein noch nicht klassifiziertes Objekt einer Klasse zuzuordnen (Klassifizierung). Der Algorithmus genannt KNN (von K-Nächste-Nachbarn, K-Next-Neighbor) funktioniert folgendermassen: Als erstes definiert man auf Grund der Attribute einen "Abstand", der ein Mass für die Gemeinsamkeit von zwei Objekten sein soll. Handelt es sich bei den Attributen beispielsweise um zwei numerische Werte, so können diese als Koordinaten in einem rechtwinkligen Koordinatensystem aufgefasst werden und als Abstand ihre geometrische Distanz (gemäss dem Satz von Pythagoras) vereinbart werden. Man geht von einer Trainings-Datensammlung X mit möglichst vielen Objekten aus, die bereits klassifiziert sind. Ein neues Objekt z klassifiziert man wie folgt: Man bestimmt die Distanz von z zu jedem Objekt aus X und nimmt die k Objekte, die die kleineste Distanz aufweisen (die k nächsten Nachbarn). Dann führt man unter diesen k Objekten eine "Abstimmung" über ihre Klassenzugehörigkeit durch. Die Klasse, die am häufigsten vorkommt, "gewinnt" und man ordnet das neue Objekt zu dieser Klasse zu. (Bei einem "Unentschieden" wählt man zufällig aus den "Gewinnern".) |
|
|
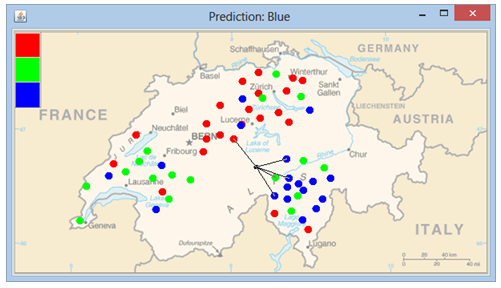
Klassifizierung von Einwohnern |
|
Das KNN-Verfahren lässt sich anschaulich an Personen demonstrieren, von denen man den Wohnort mit zwei Attributen (geografische Länge und Breite) erfasst. Der Abstand zweier Objekte ist dann gerade die Distanz (in km) der beiden Wohnorte. Wir erfassen drei Klassen Rot, Grün, Blau von Personen (aus 3 Sprachregionen deutsch-französisch-italienisch). Zuerst kann man die Trainings-Datensammlung selbst erstellen, indem man mit der Maus die Klasse (Farbe) wählt und dann die Person auf der Landkarte mit einem Klick absetzt. Mit einem Rechtsklick wird eine neue Person mit dem KNN-Algorithmus einer der drei Klassen zugeordenet. Zur Demontration wird wird der neue Datenpunkt zudem mit den k nächsten Nachbarn mit einer Linie verbunden. Programm: [►] # People.py from gpanel import * from operator import itemgetter datafile = "swisspeople.dat" bgImage = "swissmap.png" k = 5 # number of nearest neighbors fLong = 60 # scale factor for longitude (km / degree) fLatt = 80 # scale factor for lattitue (km / degree) def euklidian(pt1, pt2): return math.sqrt(fLong * (pt1[0] - pt2[0]) * fLong * (pt1[0] - pt2[0]) + \ fLatt * (pt1[1] - pt2[1]) * fLatt * (pt1[1] - pt2[1])) def onMousePressed(x, y): global color global cx, cy, xorMode # erase if xorMode: pos(cx, cy) fillCircle(0.03) # erase test person for pair in pairs: # erase proximity lines line(pair[0], pair[1], pair[2], pair[3]) setPaintMode() xorMode = False setColor(color) if isLeftMouseButton(): if x < 5.34 and y > 47.24: # color choice if y < 47.44: color = "Blue" elif y > 47.44 and y < 47.66: color = "Green" elif y > 47.66: color = "Red" setColor(color) title(color + " color selected") else: # draw people pos(x, y) fillCircle(0.05) saveSample(x, y, color) else: # right button -> make prediction setXORMode("white") xorMode = True pos(x, y) cx = x cy = y setColor("lightgreen") fillCircle(0.03) # show test person predict(x, y) def loadData(fileName): try: fData = open(fileName, 'r') except: return [] out = [] for line in fData: line = line[:-1] # remove \n li = [i for i in line.split(";")] out.append(li) fData.close() return out def predict(x0, y0): global pairs X = loadData(datafile) if len(X) < k: # not enough people for prediction return distances = [] for i in range(len(X)): pt0 = [x0, y0] pt = [float(X[i][0]), float(X[i][1])] distance = euklidian(pt0, pt) distances.append([i, distance]) sorted_distances = sorted(distances, key = itemgetter(1)) nearestPeople = [] for i in range(k): nearestPeople.append(sorted_distances[i][0]) pairs = [] votes = [0, 0, 0] for i in range(k): x = float(X[nearestPeople[i]][0]) y = float(X[nearestPeople[i]][1]) pairs.append([x0, y0, x, y]) line(x0, y0, x, y) # draw proximity lines # get votes if X[nearestPeople[i]][2] == "Red": votes[0] += 1 elif X[nearestPeople[i]][2] == "Green": votes[1] += 1 elif X[nearestPeople[i]][2] == "Blue": votes[2] += 1 max_value = max(votes) max_indices = [] for i in range(3): if votes[i] == max_value: max_indices.append(i) # all indices with max prediction = "Prediction: " for index in max_indices: if index == 0: prediction += "Red " elif index == 1: prediction += "Green " elif index == 2: prediction += "Blue " title(prediction) def saveSample(x, y, kind): fOut = open(datafile, "a") fOut.write(str(x) + ";" + str(y) + ";" + kind + "\n") fOut.close() xmin = 5 xmax = 11 ymin = 45.8 ymax = 47.9 cx = -1 cy = -1 xorMode = False pairs = [] makeGPanel(Size(594, 306), mousePressed = onMousePressed) color = "Red" title(color + " color selected") setColor(color) image(bgImage, 0, 0) window(xmin, xmax, ymin, ymax) # draw people already present X = loadData(datafile) for person in X: pos(float(person[0]), float(person[1])) setColor(person[2]) fillCircle(0.05) keep()
Bemerkungen: |
|
|
Klassifizierung von Iris-Blumen |
|
In Vorträgen und Lehrbüchern über Data Mining wird oft das Beispiel der Klassifizierung von Iris-Blumen herangezogen, da es illustrativ und wissenschaftlich von Bedeutung ist. Es stützt sich auf die Untersuchung von 3 Arten von Iris-Blumen, der Arten iris-setosa, iris-versicolor und iris-virginica
Dabei werden 4 Grössen vermessen: Länge (length h) und Breite (width w) des Blütenblatts (petal) und des Kelchblatts (sepal).
MIn der Datei iris.csv, die von hier heruntergeladen werden kann, speichert man für 150 Messungen die 4 Messwerte (als Dezimalzahl in cm) und die Blumenart, also typisch: 5.1,3.5,1.4,0.2,Iris-setosa Das Programm lädt die Datensammlung und teilt sie in einen Trainings-Set und einen Test-Set gemäss einer vorgebbaren Aufteilung. Üblicherweise verwendet man ungefähr 20% der Daten als Test-Set. (Die Aufteilung ist zufällig, aber es werden von den 3 Sorten je gleichviele Datensätze (Instanzen) übernommen.) Nachher wird gemäss dem KNN-Algorithmus für jede Instanz des Test-Sets die Klasse (Blumenart) bestimmt und geprüft, ob die Voraussage richtig ist. Am Schluss wird ausgeschrieben, mit welchem Prozentsatz die Voraussage stimmt. Programm: [►] # IrisClassification.py from operator import itemgetter import math import random datafile = "iris.csv" k = 3 # number of nearest neighbors trainingQuota = 0.8 # relativ size of training set def loadData(fileName): try: fData = open(fileName, 'r') except: return [] out = [] for line in fData: line = line[:-1] # remove \n if len(line) == 0: # empty line continue li = [i for i in line.split(",")] out.append(li) fData.close() return out def predict(sample): distances = [] for i in range(len(trainingSet)): sum = 0 for k in range(4): dk = float(trainingSet[i][k]) - float(sample[k]) sum += dk * dk distance = math.sqrt(sum) distances.append([i, distance]) sorted_distances = sorted(distances, key = itemgetter(1)) nearestSamples = [] for i in range(k): nearestSamples.append(sorted_distances[i][0]) votes = [0, 0, 0] for i in range(k): # get votes if trainingSet[nearestSamples[i]][4] == "Iris-setosa": votes[0] += 1 elif trainingSet[nearestSamples[i]][4] == "Iris-versicolor": votes[1] += 1 elif trainingSet[nearestSamples[i]][4] == "Iris-virginica": votes[2] += 1 max_value = max(votes) max_index = votes.index(max_value) if max_index == 0: return "Iris-setosa" elif max_index == 1: return "Iris-versicolor" elif max_index == 2: return "Iris-virginica" def splitSet(X, quota): randIndex = range(len(X)) random.shuffle(randIndex) nbData = len(X) nbTraining = int(quota * nbData) training = [X[i] for i in randIndex[0:nbTraining]] test = [X[i] for i in randIndex[nbTraining:nbData]] return training, test X = loadData(datafile) trainingSet, testSet = splitSet(X, trainingQuota) success = 0 for sample in testSet: p = predict(sample) if p == sample[4]: success += 1 print "Training set of size", len(trainingSet), \ Für einen typischen Run erhält man erstaunlich gute Resultate: Training set of size 120 . Test set of size 30 |
|
|
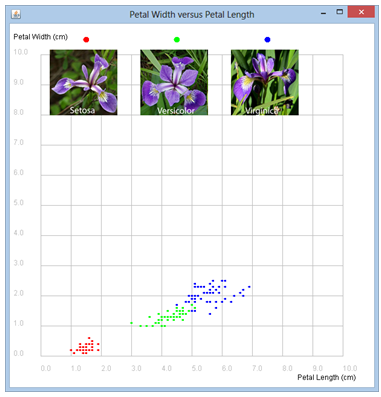
Scatterdiagramm in zwei Dimensionen |
|
Leider lassen sich die Objekte nicht wie im Beispiel mit den Personen als Punkte darstellen, da man dazu einen 4-dimensionale Raum braucht. Man kann aber jeweils zwei der 4 Messgrössen wählen und die Punkte in einem x-y-Plot auftragen. Je nach Wahl der 2 Messgrössen (es gibt 6 Möglichkeiten) ergibt sich eine andere Darstellung. In der Liste xy kann man die zwei gewünschten Koordinaten auswählen. Programm: [►] # IrisPlot.py from gpanel import * datafile = "iris.csv" species = ["setosa", "versicolor", "virginica"] # Spezies, Gattung, Pflanzenart measurements = ["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"] colors = ["red", "green", "blue"] # Select pair of measurements to show xy = [2, 3] def loadData(fileName): try: fData = open(fileName, 'r') except: return [] out = [] for line in fData: line = line[:-1] # remove \n if len(line) == 0: # empty line continue li = [i for i in line.split(",")] out.append(li) fData.close() return out def drawLabels(): for i in range(3): setColor(colors[i]) pos(1.5 + 3 * i, 10.5) fillCircle(0.1) image(species[i] + ".png", 0.3 + 3 * i, 8) X = loadData(datafile) makeGPanel(-1, 11, -1, 11) drawGrid(0, 10.0, 0, 10.0, "gray") text(8.5, -0.8, measurements[xy[0]] + " (cm)") text(-0.9, 10.5, measurements[xy[1]] + " (cm)") drawLabels() title(measurements[xy[1]] + " versus " + measurements[xy[0]]) for sample in X: if sample[4] == "Iris-setosa": setColor("red") elif sample[4] == "Iris-versicolor": setColor("green") elif sample[4] == "Iris-virginica": setColor("blue") pos(float(sample[xy[0]]), float(sample[xy[1]])) fillCircle(0.05) Bemerkungen:
|